Print by Number: UV cut issue
9/10 工具的UV cut 問題

在幾個場合中,發現很多 i1 UV cut 版本還在使用,UV cut i1 (M2)對紙白的解釋與M0或M1差別很大,自然對G7 Gray 的認定也會產生影響,由其我的分數系統在灰平衡有大的比重,直接的M2數據就會有一些誤判;為擴大參與面,我試著在程式中做一些修正,讓M2數據也能更合理的使用這個系統。
以下為同一樣本下M0,M2的10格數據比較:
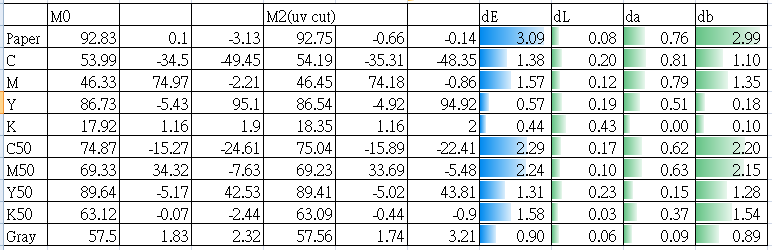
可以很快看到b*值差異較大,且紙張影響最大,紙張b*值可差到2.99;灰平衡b*值則差了0.89。
紙張a*、b*值差異直接影響到G7灰平衡目標值,M0數據的灰目標ab值為0.05,-1.6,M2灰目標ab值為-0.33,-0.07,色差為1.5。
以M2數據進到我的系統,此樣本灰度差(df)為3.88,整體分數為76.3。
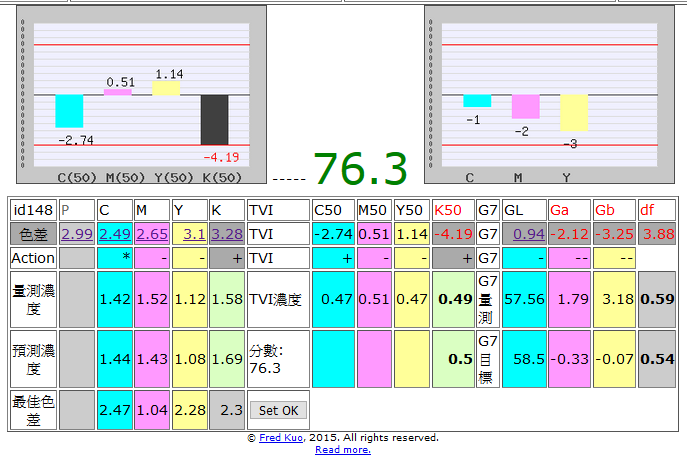
同一樣本以M0進到我的系統,樣本灰度差(df)為4.3,整體分數為73.81。

同一樣本M2數據獲得比M0數據更好的分數,但實際上M0數據更接近視覺感受;M2數據進到我的系統後,由於紙白認定的差異,會有視覺與數據不一致的情況發生。
那修正的邏輯規則在哪裡?
怎麼讓程式判斷進來的數據是M2?
修正邏輯有明顯的趨向就是紙張b*值差異很大,M2 b*值經由uv cut 擋掉短波長能量,紙白數值偏黃,b*值偏高,所以主要修正規則就是讓M2的b*值往負的方向偏一點(偏向藍色),至於要偏多少?我目前只能以一經驗數據先給予一個測試修正值,只能說目前是有效用,以後要怎麼作更系統化的修正,還待觀察;
下圖例:以同一M2數據經過修正,灰差(df)由3.88變成4.28,更接近M0數據的df:4.3;分數系統也由原本的76.3回到72.92,更接近M0數據的73.81。
如此修正,讓舊有的M2設備也能更合理的進到我的系統;擴大參與面,也是推動印刷標準(數據)化的一項重要工作。
然後我還是要重申:印刷色彩品質不必是精密科學,但數據係統一定有其必要。

再來談,如何讓程式判斷進來的數據是M2?確認是M2才會啟動修正功能?
先了解一下,所謂的OBA(Optical Briteness Agent,光學增白劑、螢光劑) 的作用是將比400nm 更短波長的能量轉移到430nm、440nm 附近,更高的能量使得紙張看起來更白,但也偏藍;uv cut 屏蔽掉400nm以下的能量,沒有 uv 能量轉移,也使得紙張數據的呈現上比較不偏藍。

回到數據觀察,同一紙張樣本,由於能量轉移,M0數據在430nm、440nm會呈現峰值,M2數據在此處則沒有峰值現象;依此規則,程式就可以判別出進來的數據是不是M2模式,如果是M2,就修飾其紙張及灰色塊的數值。
如此,完成對於M2數據的判別與修正,M2設備也能進入這個系統,擴大整個Print by Number 的參與面。
#uvCut
#擴大參與
#數據AI

Tags: idealliance g7, UV cut, 印刷標準化
無迴響
 Comments RSS
Comments RSS
 TrackBack Identifier URI
TrackBack Identifier URI
No comments. Be the first.
 Leave a comment
Leave a comment
